Sử dụng bộ sưu tập để sắp xếp ngăn nắp các trang Lưu và phân loại nội dung dựa trên lựa chọn ưu tiên của bạn.
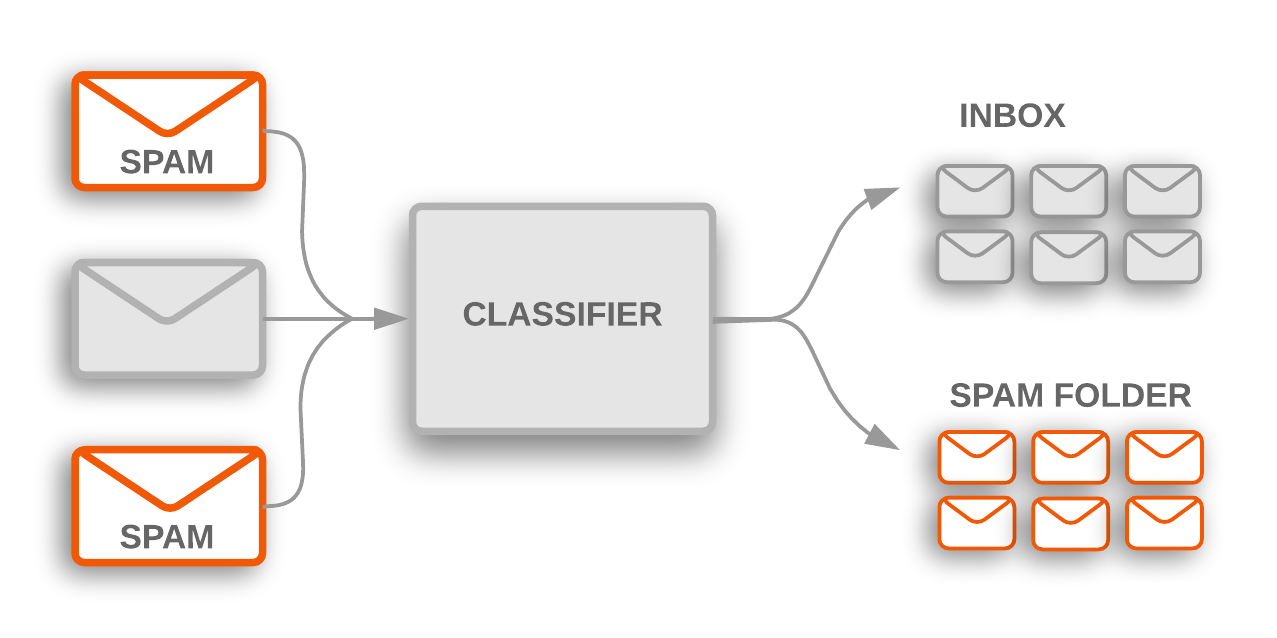
Các thuật toán phân loại văn bản là trung tâm của nhiều hệ thống phần mềm xử lý dữ liệu văn bản trên quy mô lớn. Phần mềm email sử dụng tính năng phân loại văn bản để xác định xem thư đến có được gửi tới hộp thư đến hay được lọc vào thư mục thư rác. Các diễn đàn thảo luận sử dụng cách phân loại văn bản để xác định xem có nên gắn cờ nhận xét là không phù hợp hay không.
Đây là hai ví dụ về việc phân loại chủ đề, phân loại tài liệu văn bản thành một trong những nhóm chủ đề được xác định trước. Trong nhiều vấn đề về phân loại chủ đề, cách phân loại này chủ yếu dựa trên từ khoá trong văn bản.
Hình 1: Phân loại chủ đề được dùng để gắn cờ các email rác gửi đến và được lọc vào một thư mục thư rác.
Một loại phân loại văn bản phổ biến khác là phân tích ý kiến, mục tiêu của Google là xác định cực của nội dung văn bản: loại ý kiến mà nội dung này thể hiện. Điểm này có thể ở dạng điểm xếp hạng nhị phân như/không thích hoặc một bộ tuỳ chọn chi tiết hơn, chẳng hạn như điểm xếp hạng theo sao từ 1 đến 5. Ví dụ về việc phân tích tình cảm bao gồm việc phân tích các bài đăng trên Twitter để xác định xem mọi người có thích bộ phim Black Panther hay không ngoại suy ý kiến của công chúng về một thương hiệu giày Nike mới thông qua các bài đánh giá trên Walmart.
Hướng dẫn này sẽ hướng dẫn bạn một số phương pháp hay nhất về công nghệ máy học để giải quyết các vấn đề về phân loại văn bản. Sau đây là những nội dung bạn sẽ tìm hiểu:
Quy trình làm việc cấp cao, toàn diện để giải quyết các vấn đề về việc phân loại văn bản bằng cách sử dụng công nghệ máy học
Cách chọn mô hình phù hợp cho vấn đề về việc phân loại văn bản
Cách triển khai mô hình lựa chọn bằng TensorFlow
Quy trình phân loại văn bản
Dưới đây là thông tin tổng quan cấp cao về quy trình công việc dùng để giải quyết các vấn đề về máy học:
[[["Dễ hiểu","easyToUnderstand","thumb-up"],["Giúp tôi giải quyết được vấn đề","solvedMyProblem","thumb-up"],["Khác","otherUp","thumb-up"]],[["Thiếu thông tin tôi cần","missingTheInformationINeed","thumb-down"],["Quá phức tạp/quá nhiều bước","tooComplicatedTooManySteps","thumb-down"],["Đã lỗi thời","outOfDate","thumb-down"],["Vấn đề về bản dịch","translationIssue","thumb-down"],["Vấn đề về mẫu/mã","samplesCodeIssue","thumb-down"],["Khác","otherDown","thumb-down"]],["Cập nhật lần gần đây nhất: 2022-09-27 UTC."],[[["\u003cp\u003eText classification algorithms are widely used to categorize text data, with applications like spam filtering and content moderation.\u003c/p\u003e\n"],["\u003cp\u003eTopic classification and sentiment analysis are two common types of text classification, focusing on categorizing text into predefined topics and identifying the sentiment expressed, respectively.\u003c/p\u003e\n"],["\u003cp\u003eThis guide provides a comprehensive workflow for solving text classification problems using machine learning, including data gathering, exploration, preparation, model building, training, evaluation, hyperparameter tuning, and deployment.\u003c/p\u003e\n"],["\u003cp\u003eChoosing the right machine learning model is crucial for effective text classification and is discussed in detail within the guide.\u003c/p\u003e\n"],["\u003cp\u003eTensorFlow is used to implement the chosen model for practical application in text classification tasks.\u003c/p\u003e\n"]]],[],null,["# Introduction\n\nText classification algorithms are at the heart of a variety of software\nsystems that process text data at scale. Email software uses text classification\nto determine whether incoming mail is sent to the inbox or filtered into the\nspam folder. Discussion forums use text classification to determine whether\ncomments should be flagged as inappropriate.\n\nThese are two examples of topic classification, categorizing a text document\ninto one of a predefined set of topics. In many topic classification problems,\nthis categorization is based primarily on keywords in the text.\n\n**Figure 1: Topic classification is used to flag incoming spam emails, which\nare filtered into a spam folder.**\n\nAnother common type of text classification is ***sentiment analysis***, whose\ngoal is to identify the polarity of text content: the type of opinion it\nexpresses. This can take the form of a binary like/dislike rating, or a more\ngranular set of options, such as a star rating from 1 to 5. Examples of\nsentiment analysis include analyzing Twitter posts to determine if people\nliked the Black Panther movie, or extrapolating the general public's opinion\nof a new brand of Nike shoes from Walmart reviews.\n\nThis guide will teach you some key machine learning best practices for solving\ntext classification problems. Here's what you'll learn:\n\n- The high-level, end-to-end workflow for solving text classification problems using machine learning\n- How to choose the right model for your text classification problem\n- How to implement your model of choice using TensorFlow\n\nText Classification Workflow\n----------------------------\n\nHere's a high-level overview of the workflow used to solve machine learning problems:\n\n- [Step 1: Gather Data](/machine-learning/guides/text-classification/step-1)\n- [Step 2: Explore Your Data](/machine-learning/guides/text-classification/step-2)\n- *[Step 2.5: Choose a Model\\*](/machine-learning/guides/text-classification/step-2-5)*\n- [Step 3: Prepare Your Data](/machine-learning/guides/text-classification/step-3)\n- [Step 4: Build, Train, and Evaluate Your Model](/machine-learning/guides/text-classification/step-4)\n- [Step 5: Tune Hyperparameters](/machine-learning/guides/text-classification/step-5)\n- [Step 6: Deploy Your Model](/machine-learning/guides/text-classification/step-6)\n\n**Figure 2: Workflow for solving machine learning problems**\n| \"Choose a model\" is not a formal step of the traditional machine learning workflow; however, selecting an appropriate model for your problem is a critical task that clarifies and simplifies the work in the steps that follow.\n\nThe following sections explain each step in detail, and how to implement them for text data."]]