
In diesem Beitrag wird die experimentelle WebGPU API anhand von Beispielen erläutert. Außerdem erfahren Sie, wie Sie mit datenparallelen Berechnungen auf der GPU beginnen können.

Veröffentlicht: 28. August 2019, zuletzt aktualisiert: 12. August 2025
Hintergrund
Wie Sie vielleicht schon wissen, ist der Grafikprozessor (GPU) ein elektronisches Subsystem in einem Computer, das ursprünglich für die Verarbeitung von Grafiken entwickelt wurde. In den letzten zehn Jahren hat sich die GPU jedoch zu einer flexibleren Architektur entwickelt, die es Entwicklern ermöglicht, viele Arten von Algorithmen zu implementieren, nicht nur zum Rendern von 3D-Grafiken, und dabei die einzigartige Architektur der GPU zu nutzen. Diese Funktionen werden als GPU-Computing bezeichnet. Die Verwendung einer GPU als Coprozessor für wissenschaftliche Berechnungen wird als GPGPU-Programmierung (General-Purpose GPU) bezeichnet.
GPU Compute hat maßgeblich zum jüngsten Boom im Bereich des maschinellen Lernens beigetragen, da Convolutional Neural Networks und andere Modelle die Architektur nutzen können, um effizienter auf GPUs ausgeführt zu werden. Da die aktuelle Webplattform keine GPU-Compute-Funktionen bietet, entwickelt die W3C-Community-Gruppe „GPU for the Web“ eine API, um die modernen GPU-APIs verfügbar zu machen, die auf den meisten aktuellen Geräten verfügbar sind. Diese API heißt WebGPU.
WebGPU ist eine untergeordnete API wie WebGL. Es ist sehr leistungsstark und, wie Sie sehen werden, auch sehr ausführlich. Das ist auch vollkommen in Ordnung. Wir suchen nach Leistung.
In diesem Artikel konzentriere ich mich auf den GPU-Compute-Teil von WebGPU. Ich kratze aber nur an der Oberfläche, damit Sie selbst damit experimentieren können. In den nächsten Artikeln werde ich genauer auf das WebGPU-Rendering (Canvas, Textur usw.) eingehen.
Auf die GPU zugreifen
Der Zugriff auf die GPU ist in WebGPU ganz einfach. Beim Aufrufen von navigator.gpu.requestAdapter() wird ein JavaScript-Promise zurückgegeben, das asynchron mit einem GPU-Adapter aufgelöst wird. Stellen Sie sich diesen Adapter als Grafikkarte vor. Sie kann entweder integriert (auf demselben Chip wie die CPU) oder diskret (in der Regel eine PCIe-Karte, die leistungsstärker ist, aber mehr Strom verbraucht) sein.
Sobald Sie den GPU-Adapter haben, rufen Sie adapter.requestDevice() auf, um ein Promise zu erhalten, das mit einem GPU-Gerät aufgelöst wird, das Sie für GPU-Berechnungen verwenden.
const adapter = await navigator.gpu.requestAdapter(); if (!adapter) { return; } const device = await adapter.requestDevice(); Beide Funktionen akzeptieren Optionen, mit denen Sie die Art des Adapters (Stromversorgung) und des Geräts (Erweiterungen, Grenzwerte) angeben können, die Sie benötigen. Der Einfachheit halber verwenden wir in diesem Artikel die Standardoptionen.
Schreibpuffer
Sehen wir uns an, wie Sie mit JavaScript Daten in den GPU-Arbeitsspeicher schreiben. Dieser Prozess ist aufgrund des in modernen Webbrowsern verwendeten Sandbox-Modells nicht einfach.
Im folgenden Beispiel wird gezeigt, wie vier Byte in den Pufferspeicher geschrieben werden, auf den die GPU zugreifen kann. Es ruft device.createBuffer() auf, das die Größe des Puffers und seine Verwendung berücksichtigt. Obwohl das Nutzungsflag GPUBufferUsage.MAP_WRITE für diesen bestimmten Aufruf nicht erforderlich ist, möchten wir explizit angeben, dass wir in diesen Puffer schreiben möchten. Dadurch wird ein GPU-Pufferobjekt erstellt, das bei der Erstellung zugeordnet wird, da mappedAtCreation auf „true“ gesetzt ist. Der zugehörige Rohdatenpuffer kann dann durch Aufrufen der GPU-Puffermethode getMappedRange() abgerufen werden.
Das Schreiben von Byte ist Ihnen vielleicht schon von ArrayBuffer bekannt. Verwenden Sie ein TypedArray und kopieren Sie die Werte hinein.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing. const gpuBuffer = device.createBuffer({ mappedAtCreation: true, size: 4, usage: GPUBufferUsage.MAP_WRITE }); const arrayBuffer = gpuBuffer.getMappedRange(); // Write bytes to buffer. new Uint8Array(arrayBuffer).set([0, 1, 2, 3]); An diesem Punkt wird der GPU-Puffer zugeordnet. Das bedeutet, dass er der CPU gehört und über JavaScript im Lese-/Schreibmodus darauf zugegriffen werden kann. Damit die GPU darauf zugreifen kann, muss sie die Zuordnung aufheben. Dazu rufen Sie einfach gpuBuffer.unmap() auf.
Das Konzept von „zugeordnet“/„nicht zugeordnet“ ist erforderlich, um Wettlaufsituationen zu vermeiden, in denen GPU und CPU gleichzeitig auf den Arbeitsspeicher zugreifen.
Pufferspeicher lesen
Sehen wir uns nun an, wie Sie einen GPU-Puffer in einen anderen GPU-Puffer kopieren und ihn wieder lesen.
Da wir in den ersten GPU-Puffer schreiben und ihn in einen zweiten GPU-Puffer kopieren möchten, ist ein neues Usage-Flag GPUBufferUsage.COPY_SRC erforderlich. Der zweite GPU-Puffer wird dieses Mal mit device.createBuffer() in einem nicht zugeordneten Zustand erstellt. Das Nutzungsflag ist GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ, da es als Ziel des ersten GPU-Puffers verwendet und in JavaScript gelesen wird, sobald die GPU-Kopierbefehle ausgeführt wurden.
// Get a GPU buffer in a mapped state and an arrayBuffer for writing. const gpuWriteBuffer = device.createBuffer({ mappedAtCreation: true, size: 4, usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC }); const arrayBuffer = gpuWriteBuffer.getMappedRange(); // Write bytes to buffer. new Uint8Array(arrayBuffer).set([0, 1, 2, 3]); // Unmap buffer so that it can be used later for copy. gpuWriteBuffer.unmap(); // Get a GPU buffer for reading in an unmapped state. const gpuReadBuffer = device.createBuffer({ size: 4, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ }); Da die GPU ein unabhängiger Coprozessor ist, werden alle GPU-Befehle asynchron ausgeführt. Aus diesem Grund wird eine Liste von GPU-Befehlen erstellt und bei Bedarf in Batches gesendet. In WebGPU ist der GPU-Befehlscoder, der von device.createCommandEncoder() zurückgegeben wird, das JavaScript-Objekt, das einen Batch von „gepufferten“ Befehlen erstellt, die irgendwann an die GPU gesendet werden. Die Methoden für GPUBuffer sind dagegen „ungepuffert“, d. h., sie werden atomar ausgeführt, wenn sie aufgerufen werden.
Sobald Sie den GPU-Befehlscoder haben, rufen Sie copyEncoder.copyBufferToBuffer() wie unten gezeigt auf, um diesen Befehl der Befehlswarteschlange zur späteren Ausführung hinzuzufügen. Schließen Sie die Codierungsbefehle schließlich mit dem Aufruf von copyEncoder.finish() ab und senden Sie sie an die Befehlswarteschlange des GPU-Geräts. Die Warteschlange ist für die Verarbeitung von Einreichungen über device.queue.submit() mit den GPU-Befehlen als Argumente verantwortlich. Dadurch werden alle im Array gespeicherten Befehle in der Reihenfolge atomar ausgeführt.
// Encode commands for copying buffer to buffer. const copyEncoder = device.createCommandEncoder(); copyEncoder.copyBufferToBuffer(gpuWriteBuffer, gpuReadBuffer); // Submit copy commands. const copyCommands = copyEncoder.finish(); device.queue.submit([copyCommands]); Zu diesem Zeitpunkt wurden GPU-Warteschlangenbefehle gesendet, aber nicht unbedingt ausgeführt. Rufen Sie gpuReadBuffer.mapAsync() mit GPUMapMode.READ auf, um den zweiten GPU-Puffer zu lesen. Es wird ein Promise zurückgegeben, das aufgelöst wird, wenn der GPU-Puffer zugeordnet ist. Rufen Sie dann den zugeordneten Bereich mit gpuReadBuffer.getMappedRange() ab, der dieselben Werte wie der erste GPU-Puffer enthält, nachdem alle in die Warteschlange eingestellten GPU-Befehle ausgeführt wurden.
// Read buffer. await gpuReadBuffer.mapAsync(GPUMapMode.READ); const copyArrayBuffer = gpuReadBuffer.getMappedRange(); console.log(new Uint8Array(copyArrayBuffer)); Hier können Sie dieses Beispiel ausprobieren.
Kurz gesagt: Das müssen Sie bei Puffer-Speichervorgängen beachten:
- GPU-Puffer müssen entladen werden, damit sie in der Geräte-Warteschlange verwendet werden können.
- Wenn GPU-Puffer zugeordnet sind, können sie in JavaScript gelesen und geschrieben werden.
- GPU-Puffer werden zugeordnet, wenn
mapAsync()undcreateBuffer()mitmappedAtCreationauf „true“ aufgerufen werden.
Shader-Programmierung
Programme, die auf der GPU ausgeführt werden und nur Berechnungen durchführen (und keine Dreiecke zeichnen), werden als Compute-Shader bezeichnet. Sie werden parallel von Hunderten von GPU-Kernen (die kleiner als CPU-Kerne sind) ausgeführt, die zusammenarbeiten, um Daten zu verarbeiten. Ihre Ein- und Ausgabe sind Puffer in WebGPU.
Um die Verwendung von Compute-Shadern in WebGPU zu veranschaulichen, werden wir uns mit der Matrixmultiplikation beschäftigen, einem gängigen Algorithmus im maschinellen Lernen, der unten dargestellt ist.

Kurz gesagt, werden wir Folgendes tun:
- Erstellen Sie drei GPU-Puffer (zwei für die zu multiplizierenden Matrizen und einen für die Ergebnismatrix).
- Beschreiben Sie die Ein- und Ausgabe für den Compute-Shader.
- Compute-Shader-Code kompilieren
- Compute-Pipeline einrichten
- Die codierten Befehle im Batch an die GPU senden
- GPU-Puffer der Ergebnismatrix lesen
Erstellung von GPU-Puffern
Der Einfachheit halber werden Matrizen als Liste von Gleitkommazahlen dargestellt. Das erste Element ist die Anzahl der Zeilen, das zweite die Anzahl der Spalten und der Rest die tatsächlichen Zahlen der Matrix.

Die drei GPU-Puffer sind Speicherpuffer, da wir Daten im Compute-Shader speichern und abrufen müssen. Daher enthalten die Flags für die GPU-Puffernutzung für alle GPUBufferUsage.STORAGE. Das Flag für die Verwendung der Ergebnismatrix hat auch GPUBufferUsage.COPY_SRC, da es in einen anderen Puffer kopiert wird, um gelesen zu werden, sobald alle GPU-Warteschlangenbefehle ausgeführt wurden.
const adapter = await navigator.gpu.requestAdapter(); if (!adapter) { return; } const device = await adapter.requestDevice(); // First Matrix const firstMatrix = new Float32Array([ 2 /* rows */, 4 /* columns */, 1, 2, 3, 4, 5, 6, 7, 8 ]); const gpuBufferFirstMatrix = device.createBuffer({ mappedAtCreation: true, size: firstMatrix.byteLength, usage: GPUBufferUsage.STORAGE, }); const arrayBufferFirstMatrix = gpuBufferFirstMatrix.getMappedRange(); new Float32Array(arrayBufferFirstMatrix).set(firstMatrix); gpuBufferFirstMatrix.unmap(); // Second Matrix const secondMatrix = new Float32Array([ 4 /* rows */, 2 /* columns */, 1, 2, 3, 4, 5, 6, 7, 8 ]); const gpuBufferSecondMatrix = device.createBuffer({ mappedAtCreation: true, size: secondMatrix.byteLength, usage: GPUBufferUsage.STORAGE, }); const arrayBufferSecondMatrix = gpuBufferSecondMatrix.getMappedRange(); new Float32Array(arrayBufferSecondMatrix).set(secondMatrix); gpuBufferSecondMatrix.unmap(); // Result Matrix const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]); const resultMatrixBuffer = device.createBuffer({ size: resultMatrixBufferSize, usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC }); Bindungsgruppenlayout und Bindungsgruppe
Die Konzepte von Bindungsgruppenlayout und Bindungsgruppe sind spezifisch für WebGPU. Ein Bindungsgruppenlayout definiert die vom Shader erwartete Ein-/Ausgabeschnittstelle, während eine Bindungsgruppe die tatsächlichen Ein-/Ausgabedaten für einen Shader darstellt.
Im folgenden Beispiel werden im Bindungsgruppenlayout zwei schreibgeschützte Speicherpuffer an den nummerierten Eintragsbindungen 0 und 1 sowie ein Speicherpuffer an 2 für den Compute-Shader erwartet. Die Bindungsgruppe, die für dieses Bindungsgruppenlayout definiert ist, verknüpft GPU-Puffer mit den Einträgen: gpuBufferFirstMatrix mit der Bindung 0, gpuBufferSecondMatrix mit der Bindung 1 und resultMatrixBuffer mit der Bindung 2.
const bindGroupLayout = device.createBindGroupLayout({ entries: [ { binding: 0, visibility: GPUShaderStage.COMPUTE, buffer: { type: "read-only-storage" } }, { binding: 1, visibility: GPUShaderStage.COMPUTE, buffer: { type: "read-only-storage" } }, { binding: 2, visibility: GPUShaderStage.COMPUTE, buffer: { type: "storage" } } ] }); const bindGroup = device.createBindGroup({ layout: bindGroupLayout, entries: [ { binding: 0, resource: gpuBufferFirstMatrix }, { binding: 1, resource: gpuBufferSecondMatrix }, { binding: 2, resource: resultMatrixBuffer } ] }); Compute-Shader-Code
Der Compute-Shader-Code für die Multiplikation von Matrizen ist in WGSL, der WebGPU Shader Language, geschrieben, die sich trivial in SPIR-V übersetzen lässt. Ohne ins Detail zu gehen, finden Sie unten die drei Speicherpuffer, die mit var<storage> gekennzeichnet sind. Das Programm verwendet firstMatrix und secondMatrix als Eingaben und resultMatrix als Ausgabe.
Jeder Speicherpuffer hat eine binding-Dekoration, die dem Index entspricht, der in den oben deklarierten Bindungsgruppenlayouts und Bindungsgruppen definiert ist.
const shaderModule = device.createShaderModule({ code: ` struct Matrix { size : vec2f, numbers: array<f32>, } @group(0) @binding(0) var<storage, read> firstMatrix : Matrix; @group(0) @binding(1) var<storage, read> secondMatrix : Matrix; @group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix; @compute @workgroup_size(8, 8) fn main(@builtin(global_invocation_id) global_id : vec3u) { // Guard against out-of-bounds work group sizes if (global_id.x >= u32(firstMatrix.size.x) || global_id.y >= u32(secondMatrix.size.y)) { return; } resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y); let resultCell = vec2(global_id.x, global_id.y); var result = 0.0; for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) { let a = i + resultCell.x * u32(firstMatrix.size.y); let b = resultCell.y + i * u32(secondMatrix.size.y); result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b]; } let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y); resultMatrix.numbers[index] = result; } ` }); Pipeline einrichten
Die Compute-Pipeline ist das Objekt, das den Rechenvorgang beschreibt, den wir ausführen möchten. Rufen Sie device.createComputePipeline() auf, um sie zu erstellen. Sie benötigt zwei Argumente: das zuvor erstellte Bindungsgruppenlayout und eine Berechnungsphase, die den Einstiegspunkt unseres Compute-Shaders (die main-WGSL-Funktion) und das mit device.createShaderModule() erstellte Compute-Shader-Modul definiert.
const computePipeline = device.createComputePipeline({ layout: device.createPipelineLayout({ bindGroupLayouts: [bindGroupLayout] }), compute: { module: shaderModule } }); Befehle einreichen
Nachdem wir eine Bindungsgruppe mit unseren drei GPU-Puffern und einer Compute-Pipeline mit einem Bindungsgruppenlayout instanziiert haben, ist es an der Zeit, sie zu verwenden.
Wir starten einen programmierbaren Compute-Pass-Encoder mit commandEncoder.beginComputePass(). Damit werden GPU-Befehle codiert, die die Matrixmultiplikation ausführen. Legen Sie die Pipeline mit passEncoder.setPipeline(computePipeline) und die Bindungsgruppe am Index 0 mit passEncoder.setBindGroup(0, bindGroup) fest. Der Index 0 entspricht der Dekoration group(0) im WGSL-Code.
Sehen wir uns nun an, wie dieser Compute-Shader auf der GPU ausgeführt wird. Unser Ziel ist es, dieses Programm parallel für jede Zelle der Ergebnismatrix auszuführen, Schritt für Schritt. Um beispielsweise bei einer Ergebnismatrix der Größe 16 × 32 den Ausführungsbefehl auf einem @workgroup_size(8, 8) zu codieren, rufen wir passEncoder.dispatchWorkgroups(2, 4) oder passEncoder.dispatchWorkgroups(16 / 8, 32 / 8) auf. Das erste Argument „x“ ist die erste Dimension, das zweite „y“ die zweite Dimension und das letzte „z“ die dritte Dimension, die standardmäßig auf 1 gesetzt ist, da wir sie hier nicht benötigen. In der GPU-Berechnungswelt wird das Codieren eines Befehls zum Ausführen einer Kernel-Funktion für eine Reihe von Daten als „Dispatching“ bezeichnet.
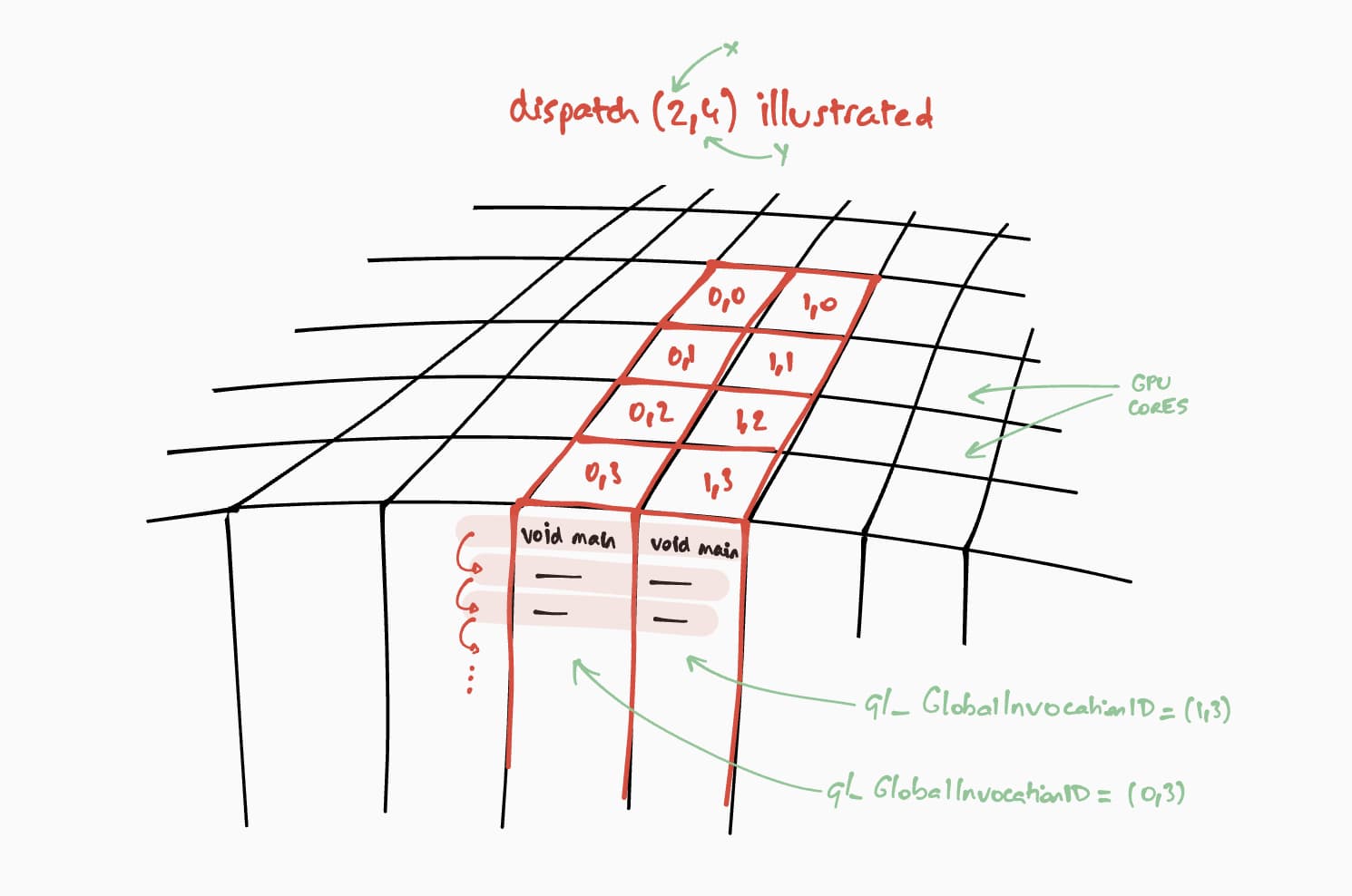
Die Größe des Arbeitsgruppen-Grids für unseren Compute-Shader ist (8, 8) in unserem WGSL-Code. Daher werden „x“ und „y“, die jeweils die Anzahl der Zeilen der ersten Matrix und die Anzahl der Spalten der zweiten Matrix sind, durch 8 geteilt. Damit können wir jetzt einen Compute-Aufruf mit passEncoder.dispatchWorkgroups(firstMatrix[0] / 8, secondMatrix[1] / 8) senden. Die Anzahl der auszuführenden Arbeitsgruppengitter ist die Anzahl der dispatchWorkgroups()-Argumente.
Wie in der Abbildung oben zu sehen ist, hat jeder Shader Zugriff auf ein eindeutiges builtin(global_invocation_id)-Objekt, mit dem ermittelt wird, welche Ergebnismatrixzelle berechnet werden soll.
const commandEncoder = device.createCommandEncoder(); const passEncoder = commandEncoder.beginComputePass(); passEncoder.setPipeline(computePipeline); passEncoder.setBindGroup(0, bindGroup); const workgroupCountX = Math.ceil(firstMatrix[0] / 8); const workgroupCountY = Math.ceil(secondMatrix[1] / 8); passEncoder.dispatchWorkgroups(workgroupCountX, workgroupCountY); passEncoder.end(); Rufen Sie passEncoder.end() auf, um den Compute-Pass-Encoder zu beenden. Erstellen Sie dann einen GPU-Puffer, der als Ziel zum Kopieren des Ergebnismatrixpuffers mit copyBufferToBuffer verwendet werden soll. Schließen Sie die Codierungsbefehle mit copyEncoder.finish() ab und senden Sie sie an die GPU-Gerätewarteschlange, indem Sie device.queue.submit() mit den GPU-Befehlen aufrufen.
// Get a GPU buffer for reading in an unmapped state. const gpuReadBuffer = device.createBuffer({ size: resultMatrixBufferSize, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ }); // Encode commands for copying buffer to buffer. commandEncoder.copyBufferToBuffer(resultMatrixBuffer, gpuReadBuffer); // Submit GPU commands. const gpuCommands = commandEncoder.finish(); device.queue.submit([gpuCommands]); Ergebnismatrix lesen
Das Lesen der Ergebnismatrix ist so einfach wie das Aufrufen von gpuReadBuffer.mapAsync() mit GPUMapMode.READ und das Warten auf die Auflösung des zurückgegebenen Promise. Dies weist darauf hin, dass der GPU-Puffer jetzt zugeordnet ist. An dieser Stelle kann der zugeordnete Bereich mit gpuReadBuffer.getMappedRange() abgerufen werden.

In unserem Code lautet das Ergebnis, das in der JavaScript-Konsole der Entwicklertools protokolliert wird, „2, 2, 50, 60, 114, 140“.
// Read buffer. await gpuReadBuffer.mapAsync(GPUMapMode.READ); const arrayBuffer = gpuReadBuffer.getMappedRange(); console.log(new Float32Array(arrayBuffer)); Glückwunsch! Sie haben es geschafft Hier kannst du das Beispiel ausprobieren.
Ein letzter Trick
Eine Möglichkeit, Ihren Code lesbarer zu machen, ist die Verwendung der praktischen Methode getBindGroupLayout der Compute-Pipeline, um das Bindungsgruppenlayout aus dem Shader-Modul abzuleiten. Dadurch entfällt die Notwendigkeit, ein benutzerdefiniertes Bindungsgruppenlayout zu erstellen und ein Pipeline-Layout in Ihrer Compute-Pipeline anzugeben, wie unten zu sehen ist.
Eine Abbildung von getBindGroupLayout für das vorherige Beispiel ist verfügbar.
const computePipeline = device.createComputePipeline({ - layout: device.createPipelineLayout({ - bindGroupLayouts: [bindGroupLayout] - }), compute: { -// Bind group layout and bind group - const bindGroupLayout = device.createBindGroupLayout({ - entries: [ - { - binding: 0, - visibility: GPUShaderStage.COMPUTE, - buffer: { - type: "read-only-storage" - } - }, - { - binding: 1, - visibility: GPUShaderStage.COMPUTE, - buffer: { - type: "read-only-storage" - } - }, - { - binding: 2, - visibility: GPUShaderStage.COMPUTE, - buffer: { - type: "storage" - } - } - ] - }); +// Bind group const bindGroup = device.createBindGroup({ - layout: bindGroupLayout, + layout: computePipeline.getBindGroupLayout(0 /* index */), entries: [ Leistungsergebnisse
Wie unterscheidet sich die Ausführung der Matrixmultiplikation auf einer GPU von der Ausführung auf einer CPU? Um das herauszufinden, habe ich das gerade beschriebene Programm für eine CPU geschrieben. Wie im Diagramm unten zu sehen ist, scheint die Nutzung der vollen GPU-Leistung eine naheliegende Wahl zu sein, wenn die Größe der Matrizen größer als 256 × 256 ist.

Dieser Artikel war nur der Anfang meiner Reise durch WebGPU. In Kürze werden weitere Artikel mit detaillierteren Informationen zu GPU Compute und zur Funktionsweise des Renderns (Canvas, Textur, Sampler) in WebGPU veröffentlicht.